

selenium应用(一):东华大学教育平台自动刷课程序(2023年秋季学期)
项目起源
大学课程的点播课可谓鸡肋,不能不看,看了又学不到什么东西。
应对此痛点开发了自动刷课程序,原理是利用selenium驱动chrome来实现真人刷课。基于egg.js框架构建,使用selenium-webdriver通过chromedriver驱动chrome。模仿真人点击刷课,规避了检测风险。先后经历开发、内测、公测阶段,发现并修改bug。后期近百位用户的使用,获得一致好评。帮助广大用户节约时间。
使用nodemailer发送邮件通知,在刷课开始、刷课出错、刷课完成都会以邮件的形式发送通知。刷课开始邮件中包含刷课进度查询链接,方便用户在刷课进程中查询。刷课出错通知中会附带错误信息,更好的debug。
技术难点一:登录验证
学习平台集成了Geetest验证,会随机弹出验证码。
.png)
前期走了很多弯路,经历过如下错误方案:
直接刷新页面,在本地是可以避开验证码,但是发到线上会一直弹出验证。也可能会刷新过多,导致页面崩溃,危害学校系统安全。
用户手动滑动,会降低使用体验,需要指定本地chrome浏览器版本。很难大规模使用。
图片识别验证码缺口位置,用程序将滑块滑到对应区域。这是一个技术含量比较高的方案,如果用Python来写会很容易,但是js的生态有限,很难完成图片识别的功能。
最终解决方案:使用二维码登录。
//找到微信登录的iframe
const iframe = await driver.wait(webdriver.until.elementLocated(By.css('iframe')), 10000);
//进入微信登录的iframe
await driver.switchTo().frame(iframe);
//获取到微信登录的图片地址
const qrcodePath = await driver.wait(webdriver.until.elementLocated(By.css('.wrp_code>img')), 10000).getAttribute('src');然后将二维码渲染到自己的页面,用户微信扫码登录,解决登录问题。

虽然最终解决问题的是一个很简单的方案,但是踩坑之路是个很长的过程。
技术难点二:性能问题
chorme早有一个称号:内存黑洞。每一个用户运行刷课程序,具体的chrome进程如下:
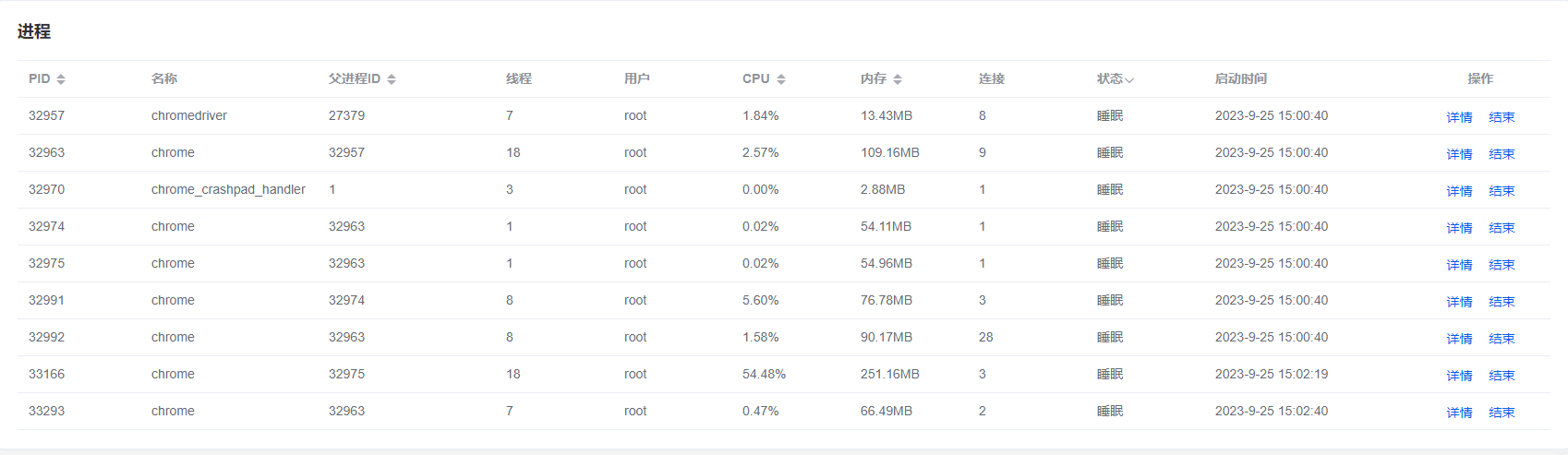 每一位用户大约需要占用700MB的内存,这是很恐怖的问题。但是学习平台的token机制是跟着浏览器走的,也就是说每一位用户都要启动一个全新的chrome进程。为了防止内存溢出,进行了如下校验:
每一位用户大约需要占用700MB的内存,这是很恐怖的问题。但是学习平台的token机制是跟着浏览器走的,也就是说每一位用户都要启动一个全新的chrome进程。为了防止内存溢出,进行了如下校验:
// 引入os模块
const os = require('os');
// 计算内存
const freememPercentage = os.freemem() / os.totalmem();
ctx.logger.info(`内存剩余:${Math.floor(freememPercentage * 10000) / 100}%`);
if (freememPercentage < 0.15) {
ctx.logger.error('内存过载');
userInfo.status = 99;
} else {
userInfo.status = 0;
}以16GB内存服务器为例:当内存占比超过85%,将用户的状态status设置为99,即为内存过载状态。此时登陆页面会提示:当前刷课人数较多,请稍后刷新重试!
还有网络性能问题,学习平台视频以TS流的形式加载,每5秒获取一次流。但是考虑到刷课进度的计时和视频是否在播放没有关联,所以不用做特殊处理。
技术难点三:多进程和进程守护
上面提到:学习平台的token机制是跟着浏览器走的,也就是说每一位用户都要启动一个全新的chrome进程。
如何保证用户A的进程不会操作到用户B的进程,也是一个需要解决的问题。
最终的解决方法是:在实例化selenium的时候,确保每位用户都是一个新的实例。
// 实例化selenium
const chromeData = new chrome.Options();
// selenium配置
chromeData.addArguments('--no-sandbox');
chromeData.excludeSwitches([ 'enable-logging' ]); // 不加载日志
if (config.env === 'prod') {
chromeData.addArguments('--headless'); // 不打开浏览器运行;
}
chromeData.addArguments('--disable-gpu'); // 禁用GPU
const By = webdriver.By;
const driver = new webdriver.Builder()
.forBrowser('chrome')
.setChromeOptions(chromeData)
.build();然后将New出来的实例driver作为函数参数,在工作流中流传。所以代码中的很多方法都有driver, By,两个参数,这就是每一个用户生成的专属实例。
还有进程守护问题,当一位用户的刷课进程因为某种原因,出现不可逆转错误,如何不让整个程序挂掉呢?
第一点是依赖于egg框架本身的进程守护,egg框架中封装了一套错误处理机制,当错误发生时,会记录到log中。这里解决的就是当一位进程的进程挂掉,不影响其他用户。
第二点就是要主动的错误处理,解决当莫个代码块出现问题,不要影响到整体流程的运行。
比如说:我们程序判断当前课程视频是否看完,是通过运行巡查程序,调用官方的接口,对比状态:
axios({
url: 'https://www.learnin.com.cn/app/user/student/course/space/overview/appStudentCourseOverview/loadCourseOutlineData',
method: 'post',
headers: {
Authorization: `Bearer ${accessToken}`
},
data: formData
})由于官方的服务器和代码运行问题,这个接口会偶尔的出现500和503的报文,但是当这个报文出现的时候,我们并不想让这个流程直接终止,所以我们要在外层使用try catch来维护程序运行,再下次巡查的时候,返回正常报文,还可以继续将流程走下去。
整个程序中try catch用了很多,大多数的原因就是为了捕获具体错误,将错误信息展示到日志中,方便debug,将错误信息的通知通过邮件发送给用户。还有就是出错后及时释放chrome进程,防止内存过载。
技术难点四:发布
关于客户端的形式曾经有两种构想:
将程序打包成exe文件,在用户本地运行,可以解决chrome负载过大的问题,还可以不使用服务器的情况下运行。
安装常规流程,将代码部署到服务器,客户端以网页的形式,只提供登录页面。
最终选择了第二种方式,首先说为什么不选择第一种:第一种方式确实减轻的服务器的负担,但是却增高了,用户可能还要关心chrome的版本问题,如果打包不善可能还需要安装node运行,这是不可以接受的。程序是给人带来便利的,不是闹心的。所以最终选择的是服务器部署,这样的程序对用户来说才是更友好的。
选择了星辰大海就要风雨兼程!chrome 的高占用注定需要一台大内存的服务器来支持,但是服务器的内存是很昂贵的,一台16GB内存的服务器对于一个个人开发者来说还是很难以接受的。最终的解决方案是用本地机器运行程序,然后通过内网穿透,将程序发布到公网使用。
这里又遇到过一个问题,我手上有两台PC、一台树莓派运行Ubuntu系统一直作为我的个人服务器使用。起初打算将树莓派作为本程序的服务器使用,因为PC需要办公娱乐使用。在部署的时候遇到问题:chrome不支持Arm架构处理器。这就要提到树莓派这个设备的情况了,只有信用卡大小的微型计算机,其系统基于Linux,树莓派自问世以来,受众多计算机发烧友的追捧,曾经一“派”难求。别看其外表“娇小”,内“芯”却很强大,视频、音频等功能通通皆有,可谓是“麻雀虽小,五脏俱全”。树莓派采用的是ubs供电,功耗很低,所以无法支持X86架构CPU,他全系搭载的都是一块Arm架构CPU,Arm也不陌生,绝大多数手机处理器、苹果的M1芯片都是Arm架构。Arm架构的Linux系统和X86架构系统具有不同的指令集,导致他们的软件并不兼容,chrome也并不支持Arm架构。

我曾尝试使用docker部署,镜像selenium/standalone-chrome支持以服务的方式使用chrome。在X86处理器上曾尝试运行,没有任何问题,但是换到Arm架构上,这个镜像构建的容器是不能运行起来的,一直报错,错误也是系统兼容的问题。
最终是用一台32GB内存的PC,使用Vmware运行Ubuntu。使用Frp内网穿透软件实现外网访问。这里还有一个细节,内网穿透有Tcp穿透和Https穿透可选,此程序是要支持Https的,理应选择Https通道穿透,但是实际操作起来,Https通道搭建要比Tcp通道要麻烦很多。解决方案更推荐于使用Tcp通道穿透,到外网服务器的时候,使用Nginx反向代理Tcp端口,实现Https访问。
server {
listen 80;
listen 443 ssl;
server_name donghua.right-house.love;
root html;
index index.html index.htm;
ssl_certificate /ssl/donghua.right-house.love.pem;
ssl_certificate_key /ssl/donghua.right-house.love.key;
ssl_session_timeout 5m;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3;
ssl_prefer_server_ciphers on;
location / {
proxy_pass http://127.0.0.1:7771/;
}
}7771端口是程序的访问端口,将域名的的根目录指向这个地址,就可以通过Https访问。
操作页面
后台管理页面
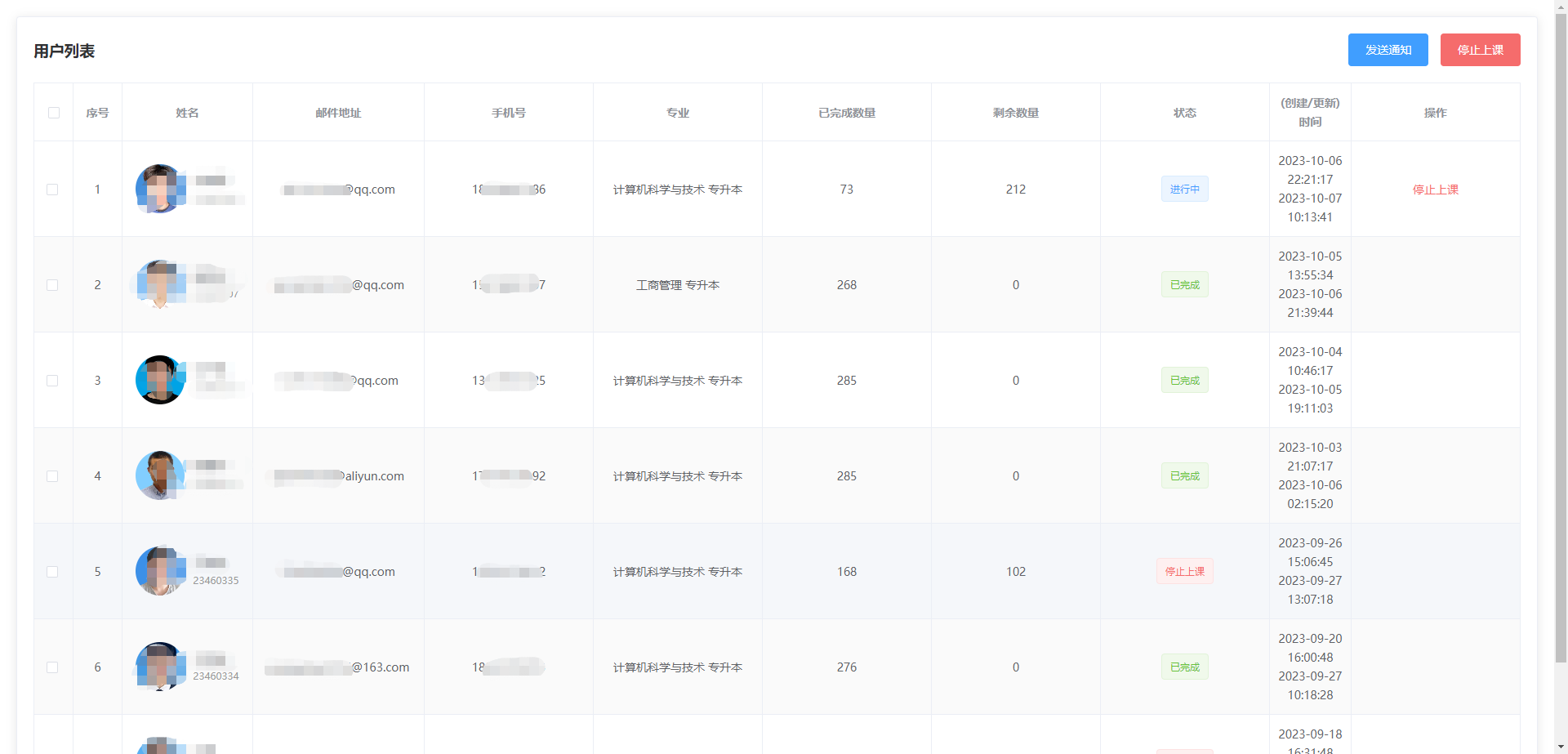 由于系统结构简单,并没有设置用户体系,后台管理系统的密码验证使用Nginx完成:
由于系统结构简单,并没有设置用户体系,后台管理系统的密码验证使用Nginx完成:
首先使用htpasswd工具生成密码文件
htpasswd -c /opt/.htpasswd liuxin
# 根据提示输入密码
# 在/opt目录下会生成htpasswd文件配置Nginx config
location /view {
proxy_pass http://127.0.0.1:7001;
auth_basic "Restricted";
auth_basic_user_file /opt/htpasswd;
}再次访问页面就会提示输入密码
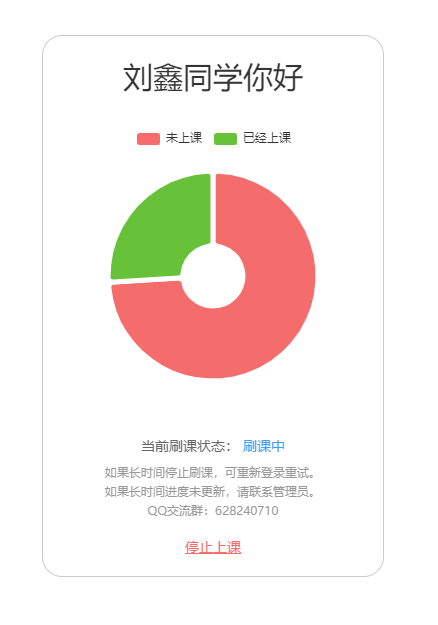
登录页/刷课进度查询页
邮件通知



